Claude Opus 4.8 vs 4.7: A Hands-On Review and Benchmarks


Claude Opus 4.8 launched on May 28, 2026, and after a day of hands-on testing on real client code, our engineering team's early read is this: it is a modest jump on paper and a clearly noticeable one in daily use. The biggest wins are cleaner reasoning, more honest code, and a model that pushes back instead of guessing.
Key takeaways
- Released: May 28, 2026, available now via the
claude-opus-4-8API model ID, claude.ai, and Amazon Bedrock. - Benchmarks: 88.6% on SWE-bench Verified and 69.2% on SWE-bench Pro, ahead of GPT-5.5 (58.6%) and Gemini 3.1 Pro (54.2%).
- Honesty: about 4 times less likely than Opus 4.7 to let a flaw in its own code slip by unremarked.
- New tools: dynamic workflows (hundreds of parallel subagents) and effort control.
- Pricing: unchanged at $5 / $25 per million tokens, and fast mode is now roughly three times cheaper.
What is Claude Opus 4.8?
Claude Opus 4.8 is Anthropic's flagship large language model, positioned as its strongest option for coding, agentic tasks, and knowledge work. It keeps the same 1,000,000-token context window, 128,000-token maximum output, and January 2026 knowledge cutoff as Opus 4.7, so the gains come from the model itself rather than a bigger context budget. Anthropic frames the release, in its own words, as a "modest but tangible improvement", a refreshingly candid line in a market full of generational hype. It arrives as the competition with OpenAI's GPT-5.5 and Google's Gemini 3.1 Pro sharpens, and Anthropic also reports new highs on its prosocial and alignment measures.
Claude Opus 4.8 vs Opus 4.7: benchmarks
The benchmark story is incremental but consistent. Every coding score moved up, and the largest gain shows up on the hardest test, which is the one that best resists memorization.
| Benchmark | Opus 4.8 | Opus 4.7 | GPT-5.5 | Gemini 3.1 Pro |
|---|---|---|---|---|
| SWE-bench Verified | 88.6% | 87.6% | – | – |
| SWE-bench Pro | 69.2% | 64.3% | 58.6% | 54.2% |
| SWE-bench Multilingual | 84.4% | 80.5% | – | – |
| Online-Mind2Web (computer use) | 84% | – | – | – |
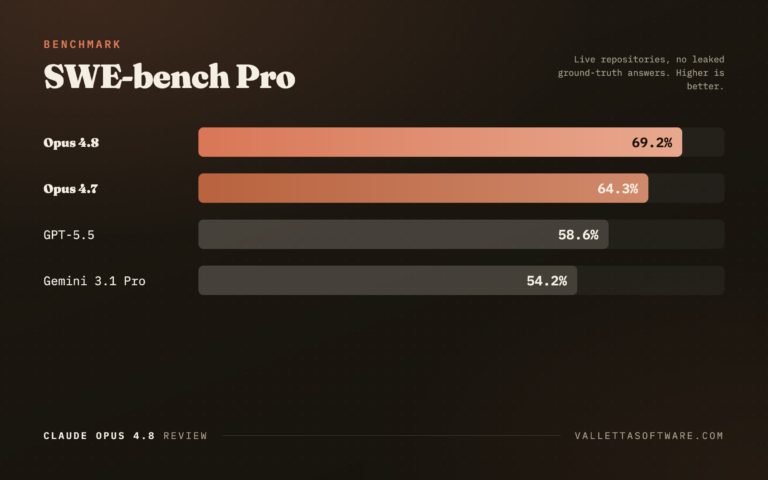
On SWE-bench Pro, the variant that pulls from live repositories without leaked ground-truth answers, Opus 4.8 lands almost 5 points ahead of 4.7 and more than 10 points clear of GPT-5.5. SWE-bench remains the most-watched public proxy for real-world coding ability, so a gain there is the one developers tend to feel.
The gap is widest on the tasks that matter most for production work: long, multi-file changes inside repositories the model has never seen. That is also where benchmark inflation is hardest, because there are no public answers to memorize. A point or two on SWE-bench Verified looks small, but on the harder Pro and Multilingual splits the lead compounds into measurably fewer broken pull requests across a sprint, which is the number our team actually tracks.
What changed that you actually feel
Benchmarks rarely capture day-to-day behavior, so here is what stood out to our team in a first day of hands-on use on real client codebases. It lines up closely with what other developers reported in the wild once the model shipped.
It is more honest about its own code
This is the upgrade we felt first. Opus 4.8 is roughly four times less likely than 4.7 to wave through a flaw in code it just wrote. Asked to fix a tangled bug, it laid out several tiers of related issues and proposed a regression-aware fix instead of patching the first symptom it found. Anthropic achieves part of this by having the model decline uncertain questions rather than bluff, which is exactly the trade-off we want in production code.
It pushes back instead of agreeing
Opus 4.8 feels more confident, occasionally bordering on overconfident. Give it a CTO-style brief and it starts making opinionated architecture calls rather than asking permission at every step. In review sessions it challenged our assumptions more often than 4.7 did. That is a real asset for senior teams, and something to watch if you have been leaning on the model to defer to you.
The reasoning is cleaner
The thinking summaries contain far less of the odd, tangential noise that 4.7 sometimes produced. For long agentic runs that means the trace is easier to audit, which matters a great deal when you are reviewing AI-written code before it ships.
Dynamic workflows and effort control
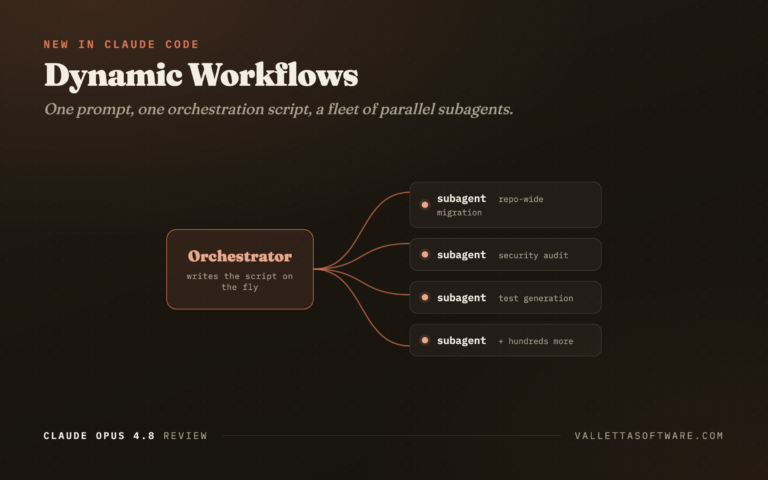
Two new capabilities ship alongside the model, and dynamic workflows is the one the developer community latched onto first. Released as a research preview in Claude Code, it works like this: you put the word "workflow" in a prompt, Claude writes an orchestration script on the fly, and it spins up a large fleet of coordinated subagents that run in parallel on your most complex tasks, things like repo-wide migrations and audits. It is available on Enterprise, Team, and Max plans. Effort control lets you dial how much computation Claude spends on a request, trading speed for depth. On the API side, system messages now work mid-conversation without breaking the prompt cache, and the minimum cacheable prompt dropped from 4,096 to 1,024 tokens, which quietly cuts cost in agent loops.
Pricing: what Opus 4.8 costs
Standard pricing is unchanged from Opus 4.7 at $5 per million input tokens and $25 per million output tokens. The bigger news is fast mode, which fell to roughly $10 per million input and $50 per million output, around a third of the previous fast-mode price. If your token spend has been climbing, our guide to controlling Anthropic token costs covers the levers that move the bill the most.
Who should upgrade to Claude Opus 4.8?
For coding and agentic work, the upgrade is easy to recommend, especially because the price did not move. Teams running automated agents benefit most, both from the honesty gains and from the cheaper fast mode. If you are shipping AI-built software, pair the model with a human review step: see our walkthrough on auditing a vibe-coded app before it goes live and our roundup of the best vibe coding tools in 2026.
Limitations to watch
It is not flawless. Some developers reported the model still hallucinating or skimming code on the most complex tasks, and the extra confidence can make a wrong answer sound certain. The classic last-10-percent problem on large legacy codebases has not vanished either. Treat Opus 4.8 as a faster, more trustworthy collaborator, not an unsupervised one, and keep a reviewer in the loop. If you are scaling a team around these tools, our guide to hiring AI developers in 2026 is a useful next read.
Frequently asked questions
Is Claude Opus 4.8 better than Opus 4.7?
Yes. It scores higher on every coding benchmark, produces cleaner reasoning, and is about four times less likely to let flaws in its own code pass unremarked, all at the same standard price as 4.7.
How much does Claude Opus 4.8 cost?
Standard usage is $5 per million input tokens and $25 per million output tokens, identical to Opus 4.7. Fast mode is now roughly $10 input and $50 output per million tokens.
What is the context window for Claude Opus 4.8?
It keeps the 1,000,000-token context window and 128,000-token maximum output from Opus 4.7, with a January 2026 knowledge cutoff.
What are dynamic workflows in Claude Opus 4.8?
Dynamic workflows let Claude Code launch hundreds of parallel subagents to handle large tasks such as codebase-wide migrations and audits. They are available on Enterprise, Team, and Max plans.
How do I access Claude Opus 4.8?
Use the model ID claude-opus-4-8 via the Anthropic API, select it in claude.ai, or access it on Amazon Bedrock.