MLOps Consulting Services: LLMs in Production, Fast

Valletta Software's MLOps consulting services move AI prototypes into production for engineering teams that already proved the model works in a notebook but cannot get it served, monitored, and improved continuously. We staff senior MLOps engineers who specialize in LLM deployment, RAG pipelines, model serving, drift monitoring, and the cost economics of GPU workloads. Most engagements start with a free 45-minute consultation.
Key takeaways
- If your model is in a notebook and you cannot ship it, you have an MLOps problem, not a modeling problem. MLOps is what we solve.
- RAG pipelines and LLM serving have their own production patterns: index freshness, prompt versioning, eval harnesses, cost-per-query monitoring.
- Our engineers come with the playbooks from prior MLOps deployments (RAG at scale, fraud detection, recommender systems, computer vision).
- Engagements scope against measurable outcomes: time-to-first-prediction, p95 latency, monthly inference cost, drift detection lag.
- We bill weekly, transparently, and never lock you to a proprietary platform.
What we do
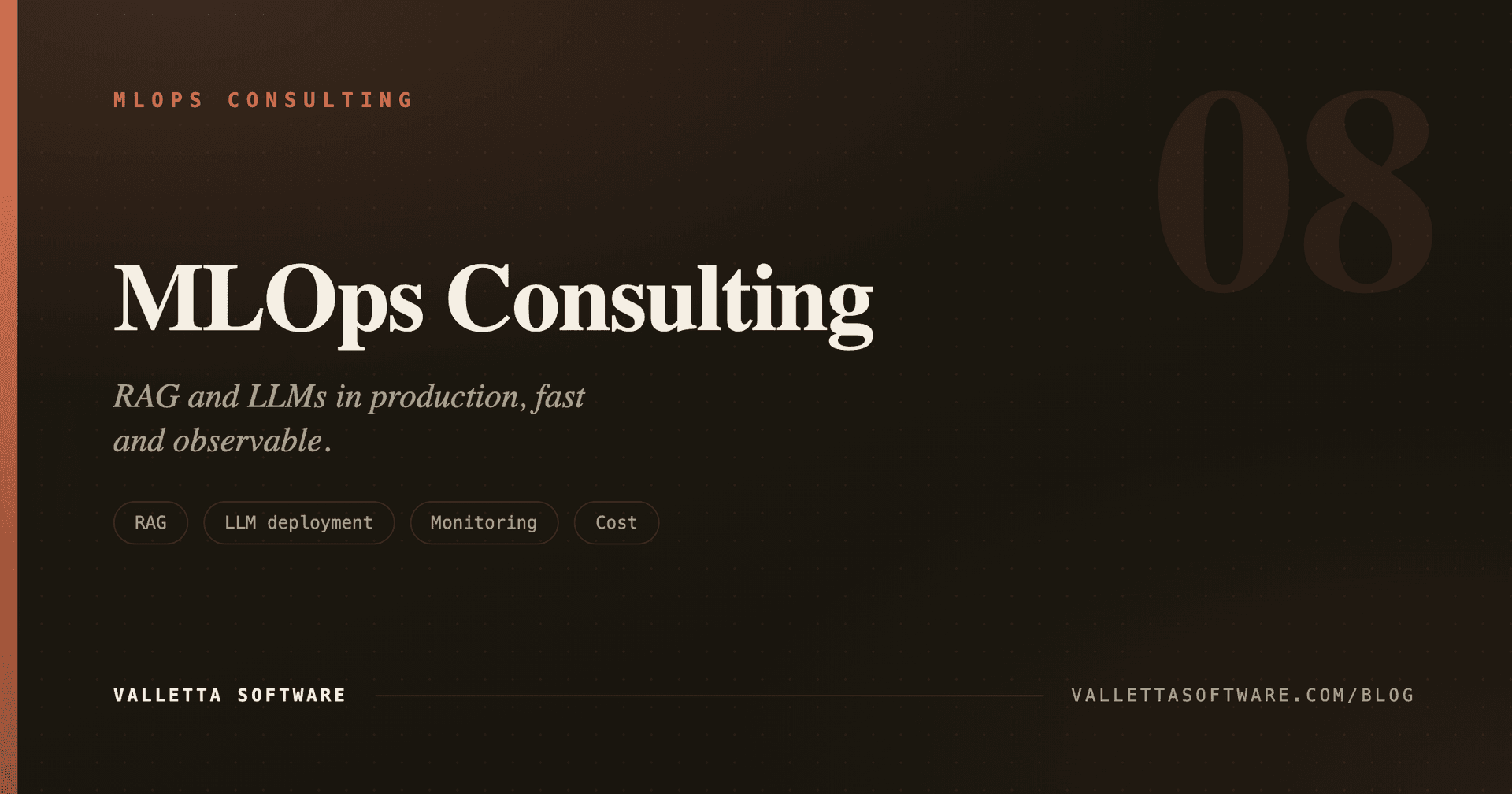
Notebook to production
The most common engagement. You have a working model. We build the training pipeline, the model registry, the deployment, and the monitoring. Typical timeline: 6 to 10 weeks to first production prediction at production-grade quality. Background reading: our MLOps explainer.
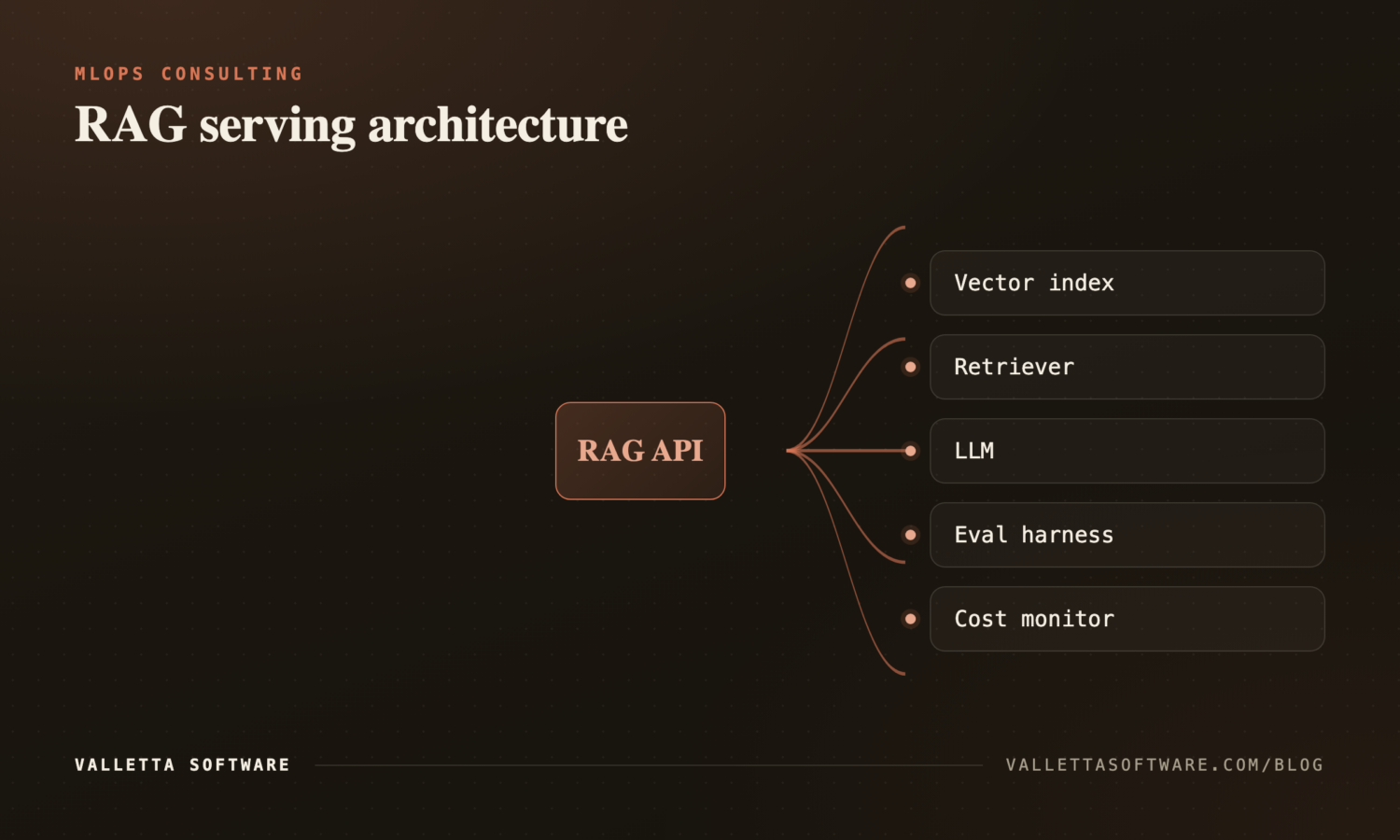
RAG and LLM production deployment
We have shipped RAG pipelines that survived launch, real users, and adversarial input. Standard stack we work with: vector store (Pinecone, Weaviate, pgvector, Qdrant), embeddings pipeline, LLM provider routing (Claude, OpenAI, open-source), prompt versioning, eval harness for hallucinations, and end-to-end observability (Langfuse, LangSmith, Helicone, OpenLLMetry). One of our reference case studies is a broken-RAG rescue (the customer was hallucinating answers in production); ask us about it on the call.
Model serving infrastructure
Real-time APIs, batch inference, or streaming. KServe, BentoML, vLLM for LLMs, Ray Serve, SageMaker Endpoints, or Vertex AI. We pick the serving stack based on your latency budget, traffic shape, and unit economics, not on what is fashionable.
Model monitoring and drift detection
System metrics (latency, error rate, GPU utilization) plus ML-specific signals (input drift, prediction drift, performance against ground truth). Tooling we work with: Arize, WhyLabs, Evidently AI, Fiddler. We design alerts that trigger retraining, not just slack messages.
GPU cost forecasting and optimization
Inference cost on LLMs adds up fast. We model your GPU spend per request, identify whether to use shared inference, dedicated capacity, or batching, and where smaller models or quantization can cut costs without quality loss. Teams often see 30 to 60% cost reductions on the inference layer.
MLOps platform builds
For teams shipping 5+ models, we build the platform underneath: MLflow or SageMaker as the registry, Airflow/Dagster/Metaflow as the orchestrator, feature store (Tecton, Feast), and the IaC behind it. Read our MLOps overview for the architecture patterns.
Who this is for
- B2B SaaS companies embedding AI features (RAG, classification, search ranking).
- AI-native startups Series A through C that built a great model and now need it to run reliably.
- Fintech, healthtech, and legaltech teams deploying models in regulated contexts (model cards, fairness, audit trails).
- Engineering teams whose data scientists are blocked because the path to production is unclear.
Why teams pick us
- Production scars. Our engineers have launched RAG and ML systems with real users. They know what breaks at 100 RPS that did not break in a notebook.
- Cost honesty. We will tell you when an open-source model is cheaper or when a 70B LLM is overkill for your task.
- Vendor neutral. Anthropic Claude, OpenAI, open-source via Hugging Face, all in scope. We pick what fits your latency, cost, and quality envelope.
- 48-hour onboarding. Pre-vetted engineers on your repo within two business days of signing.
- Senior only. 8+ years average production experience.
How engagements work
- Free consultation: 45-minute call to scope the model, the production target, and the constraints.
- Technical scoping (1 week): we review your code, your data, and your infra and propose a phased plan with deliverables.
- Build phase: typically 6 to 12 weeks. Weekly demos. We work alongside your team, not in a black box.
- Production launch: shadow mode, then canary, then full rollout. We are on call for the first two weeks post-launch.
- Handoff: runbooks, ADRs, training for your team. Optional retainer for monitoring, retraining, and new model launches.
Reference engagements
- RAG-to-production rescue for a US B2B SaaS company: hallucinations cut from 18% to 2% in 8 weeks; cost per query down 40%.
- Fraud detection model serving for a fintech: p95 latency from 800ms to 120ms; daily retraining pipeline.
- MLOps platform build for a healthtech series-C: 12 models on a unified MLflow + Airflow stack; first new model from idea to production in 9 days.
We can share more details under NDA on the consultation call.
What clients ask us first
Do you do RAG implementation specifically?
Yes. RAG is one of our most common engagements. We have shipped RAG in production for B2B SaaS, support automation, and internal knowledge tools. Index strategy, prompt versioning, evaluation harnesses, cost control, security and PII filtering are all in scope.
What about LLM production deployment for our own model?
If you are hosting an open-source or fine-tuned model, vLLM, TGI, or Ray Serve on GPUs is the standard play. We design the autoscaling, the batching, and the cost-per-request envelope.
Do you work with Anthropic Claude / OpenAI / open-source LLMs?
All of them. We help you pick based on latency, cost, quality on your eval, and the risk profile of the use case.
How is this different from a generic ML consulting firm?
We focus on the operations layer. If you need a research team to build a novel model, that is not us. If you need the model to actually serve traffic reliably, that is exactly us.
How does this fit with DevOps and platform engineering?
MLOps assumes a working DevOps foundation. If you do not have one, we can scope a joint engagement with our DevOps or platform engineering teams.
Ready to ship the model?
A 45-minute call gives us enough to tell you whether your model is ready for production and what the first 30 days of an engagement would look like.