MLOps Explained: Shipping ML Models to Production

What is MLOps? MLOps (machine learning operations) is the discipline of building, deploying, monitoring, and continuously improving machine-learning models in production using the same engineering rigor as modern DevOps. It adds the parts DevOps did not have to solve: dataset versioning, reproducible training, model registries, drift monitoring, and rollback for non-deterministic systems. MLOps is what gets a model out of a notebook and keeps it healthy under real traffic.
Key takeaways
- MLOps is DevOps for ML, plus the parts that are unique to ML: data, training, evaluation, and drift.
- The majority of ML projects never reach production. MLOps is the operating model that changes that.
- You need version control for three artifacts: code, data, and the trained model.
- Production ML systems decay. Models drift as input data shifts. Monitoring drift is as important as monitoring uptime.
- Generative AI (LLMs, RAG) added new operational surface area: prompt versions, retrieval indexes, eval harnesses, cost per request.
What is MLOps?
MLOps applies the practices of CI/CD, infrastructure as code, observability, and automated testing to the machine-learning lifecycle. It is the set of tooling and processes that lets a team go from "a data scientist trained a model in a notebook" to "the model serves predictions in production at scale, is monitored, and gets retrained when it drifts."
The term emerged around 2018 to 2020 (Google's influential 2020 paper codified the levels of MLOps maturity) as the gap between ML research and production engineering became impossible to ignore. By 2026 MLOps is its own discipline, with a tooling ecosystem (MLflow, Weights and Biases, Vertex AI, SageMaker, Databricks) and a recognized engineering role (MLOps engineer).
What does an MLOps engineer do?
An MLOps engineer owns the path from a trained model to a production system. Typical responsibilities:
- Build the training pipeline that takes code and a dataset and produces a reproducible model.
- Run the model registry where versioned models live and are promoted across environments.
- Operate the serving infrastructure (REST, gRPC, batch, streaming, or embedded).
- Set up monitoring for both system metrics (latency, errors) and ML-specific signals (input drift, prediction drift, performance against ground truth).
- Automate retraining and re-deployment when drift exceeds thresholds.
- Manage costs (GPU spend is a board-level concern at scale).
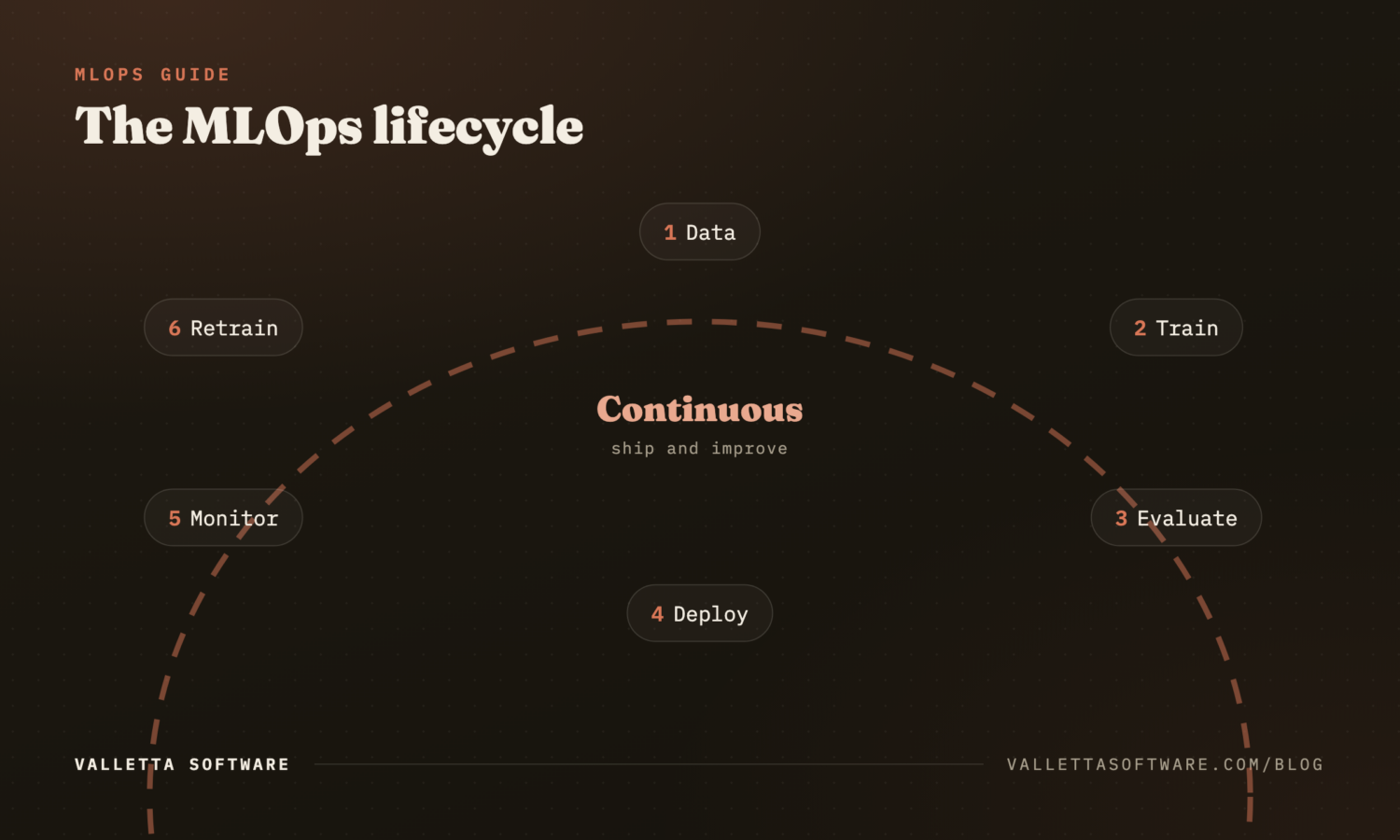
The MLOps lifecycle
The lifecycle is usually drawn as a loop:
- Problem framing. What prediction, against what business metric.
- Data collection and labeling. Often the longest and most expensive step.
- Feature engineering. Computed offline in a feature store, served online with the same definition.
- Experimentation. Many candidate models, tracked with MLflow, Weights and Biases, or Comet.
- Training. Reproducible pipeline, versioned data, hyperparameters logged.
- Evaluation. Offline metrics against a held-out set; fairness and robustness tests; cost simulations.
- Deployment. Shadow mode, then canary, then full rollout. Behind a feature flag.
- Monitoring. Performance, drift, latency, cost.
- Retraining. Triggered by drift, by new labeled data, or on a schedule.
The loop never closes. Production ML is a continuously maintained system, not a one-time delivery.
MLOps vs DevOps
The shared parts: version control, CI/CD, infrastructure as code, monitoring, on-call. MLOps inherits the entire DevOps toolchain, which is why a DevOps foundation is a prerequisite for MLOps.
The MLOps-specific parts:
- Data is part of the build. The same code with different training data produces a different model. You need data versioning (DVC, LakeFS, Delta Lake, Iceberg).
- The artifact is the model, not the binary. Models are large (sometimes tens of gigabytes), GPU-bound, and need a registry (MLflow, SageMaker Model Registry, Vertex AI Model Registry).
- Outputs are probabilistic. The same input can yield a different prediction after retraining. Testing for ML cannot rely on equality assertions; it relies on statistical comparisons.
- Drift. The model was correct at train time. As input distributions shift (new customers, seasonality, world events), accuracy decays. This is the failure mode that has no equivalent in classical DevOps.
- GPU economics. CPU-bound DevOps is cheap; GPU-bound MLOps requires explicit cost models and capacity planning.
Machine learning pipelines and orchestration
A machine learning pipeline is the end-to-end automation that turns raw data into a deployed model. The standard tooling:
- Airflow, Dagster, Prefect: general-purpose orchestrators that work well for ML.
- Kubeflow Pipelines: Kubernetes-native, geared for ML.
- Metaflow: Netflix-open-sourced; great developer experience.
- SageMaker Pipelines, Vertex AI Pipelines, Azure ML Pipelines: cloud-native, tied to that vendor's ecosystem.
Pipeline orchestration is one of the highest-leverage MLOps investments. It enforces reproducibility, captures lineage, and gives you a place to add monitoring.
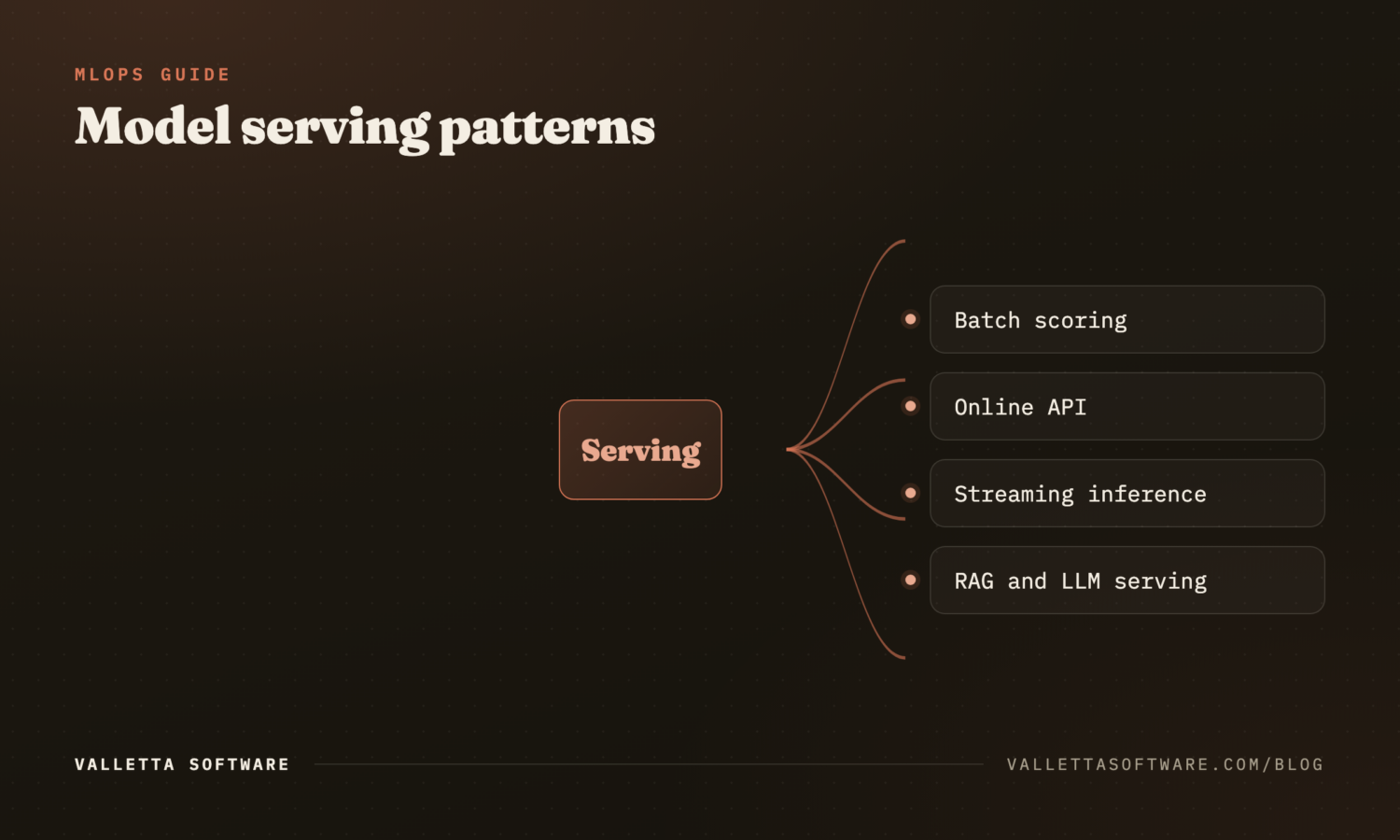
Model deployment patterns
- Real-time API. REST or gRPC, low-latency, behind an autoscaler. Use this when predictions need to happen during a user request.
- Batch inference. Schedule the model to score a dataset on a cadence. Cheaper, simpler; fine for daily product recommendations or risk scoring.
- Streaming inference. Predictions on events as they arrive (Kafka, Kinesis, Pub/Sub). Used for fraud detection, anomaly detection.
- Edge or on-device. Model runs on a phone, IoT device, or browser. Required for offline use cases and strict privacy regimes.
The choice depends on latency tolerance, traffic shape, and unit economics. Most production teams run a mix.
RAG architecture and LLM operations
Generative AI added a new operational surface. The dominant production pattern in 2026 is retrieval-augmented generation (RAG): the LLM is grounded in your own documents, not just its training data. A RAG architecture has four moving parts:
- Ingestion: source documents are chunked and embedded into a vector store (Pinecone, Weaviate, pgvector, Qdrant).
- Retrieval: at query time the user's question is embedded and the top-k most similar chunks are pulled.
- Augmentation: the retrieved chunks are pasted into the LLM prompt as context.
- Generation: the LLM (Claude, GPT, open-source) answers with the retrieved context grounding it.
RAG operations introduce specific concerns: index freshness, chunk strategy, prompt versioning, evaluation harnesses for hallucinations, cost per query, and PII filtering. Treat your prompts and your RAG configuration like code: versioned, reviewed, tested in CI.
MLOps best practices
- Version everything: code, data, models, prompts, configs.
- Feature stores in production (Tecton, Feast, Vertex Feature Store) eliminate train/serve skew.
- Shadow before canary. Run a new model in parallel and compare predictions before serving real traffic.
- Eval harnesses for LLMs. Automated tests for hallucination, toxicity, factuality on a curated set.
- Monitor business metrics, not just model metrics. Precision dropped 1%? Maybe fine. Revenue dropped 10%? Roll back.
- Plan for retraining cadence from day one.
Common MLOps pitfalls
- Notebook-driven production. A notebook is a research tool, not a deployment artifact.
- Untracked datasets. "It worked on the data we had in March" is not a reproducible result.
- No drift monitoring. The model rots silently for months until a downstream metric reveals the damage.
- One-shot deployment. Treating a model as a finished product instead of a system that needs maintenance.
- Ignoring cost. GPU-hours add up fast, especially with LLM serving.
MLOps tooling landscape in 2026
- Experiment tracking: MLflow, Weights and Biases, Comet, Neptune.
- Model registry: MLflow, SageMaker, Vertex AI Model Registry.
- Serving: KServe, BentoML, vLLM (for LLMs), Ray Serve, SageMaker Endpoints.
- Monitoring: Arize, WhyLabs, Evidently AI, Fiddler.
- Feature stores: Tecton, Feast, Vertex Feature Store.
- RAG and LLM tooling: LangSmith, Langfuse, Helicone, OpenLLMetry.
The right stack depends on your team size and where you already live (AWS, GCP, Databricks, on-prem). For practical advice on what fits your situation, see our MLOps consulting overview.
Where to start
If you have a model that needs to reach production and you do not have an MLOps stack, the first three steps are:
- Get your training reproducible. Same code + same data + same env produces the same model.
- Put your model behind a versioned API with health checks.
- Monitor a small set of metrics (latency, error rate, prediction distribution).
Everything else can come after. If you want a senior MLOps engineer to scope this work for your team, Schedule Free Consultation and we will walk through your stack.
Frequently asked questions
What is the difference between MLOps and DevOps?
DevOps automates building, testing, and deploying software. MLOps adds the parts unique to ML: data versioning, reproducible training, model registries, drift monitoring, and statistical (not equality) testing. MLOps assumes a working DevOps foundation.
Is MLOps required for small teams?
The lightweight version is, yes. Even a two-person team needs reproducible training, a registered model artifact, and basic monitoring. The heavyweight platform (Kubeflow, full feature store) is not required until model count and team size justify it.
What is an MLOps platform?
An MLOps platform is an integrated set of tools that covers the lifecycle from data to deployment. SageMaker, Vertex AI, and Databricks ML are vendor platforms. MLflow + Airflow + KServe + Arize is a popular open-source stack.
How does MLOps handle LLMs and RAG?
The same lifecycle applies, with extra concerns around prompt versioning, retrieval index freshness, hallucination evaluation, and cost monitoring. The discipline is sometimes called LLMOps but the practices overlap heavily with MLOps.
What does a production-ready model look like?
Versioned and registered, deployed behind an API with health checks, monitored for both system metrics and drift, with an automated retraining trigger, an explicit rollback procedure, and unit economics that justify the inference cost.