GEO for E-commerce: 500K Queries to AI Citations (2025)


Who this is for: Heads of Content/SEO, Product Managers, and AI/data teams who want their brand to appear inside AI answers (Google AI Overviews, ChatGPT, Perplexity, Claude), not only in classic SERPs.
Key takeaways
- 500,000 e-commerce queries analyzed across AI search engines in 2025: ChatGPT, Perplexity, Google AI Overviews.
- Citation patterns: AI overwhelmingly cites pages with structured data, FAQ blocks, and clear product specs.
- 3 GEO wins for e-commerce: Product schema with Offer prices, FAQPage on category pages, citable statistics in reviews.
- The top GEO-citation gap: e-commerce sites without FAQ schema on PDPs lose to competitors who add it.
What is GEO and why should a furniture brand care?
Generative Engine Optimization (GEO) is the discipline of creating, structuring, and amplifying content and brand signals so AI systems can confidently quote you. For DreamSofa, GEO captures zero-click demand, builds trust via consistent signals, and secures a first-mover advantage in discovery experiences where users read answers, not lists of links.
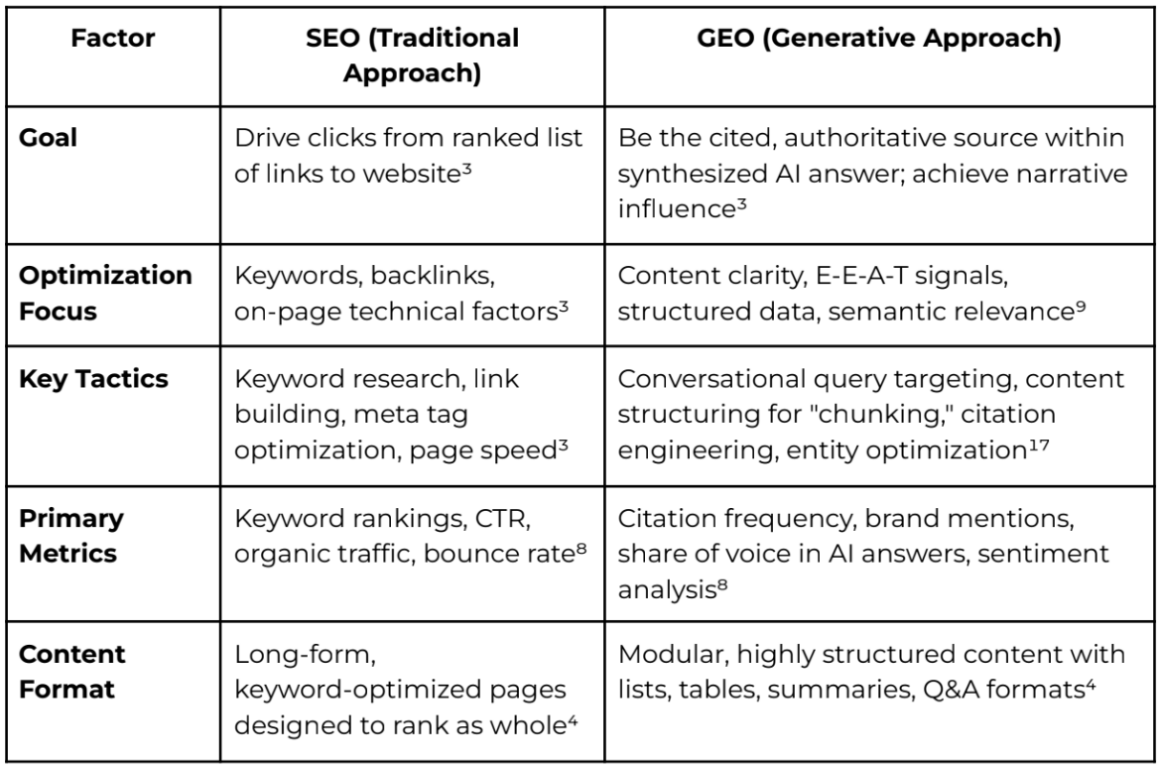
Trade-off: Choosing GEO to earn citations inside AI answers means paying for more data plumbing, stronger content governance, and ongoing knowledge-base upkeep. The cost is higher than "traditional SEO only," but your share of voice where attention is shifting can be dramatically larger.
Real-world GEO results: DreamSofa metrics (March 2026)
Theory is useful. Numbers are better. Here is what the Ahrefs dashboard shows for dreamsofa.com after activating the GEO pipeline, across AI citation surfaces, organic search, and backlink authority.
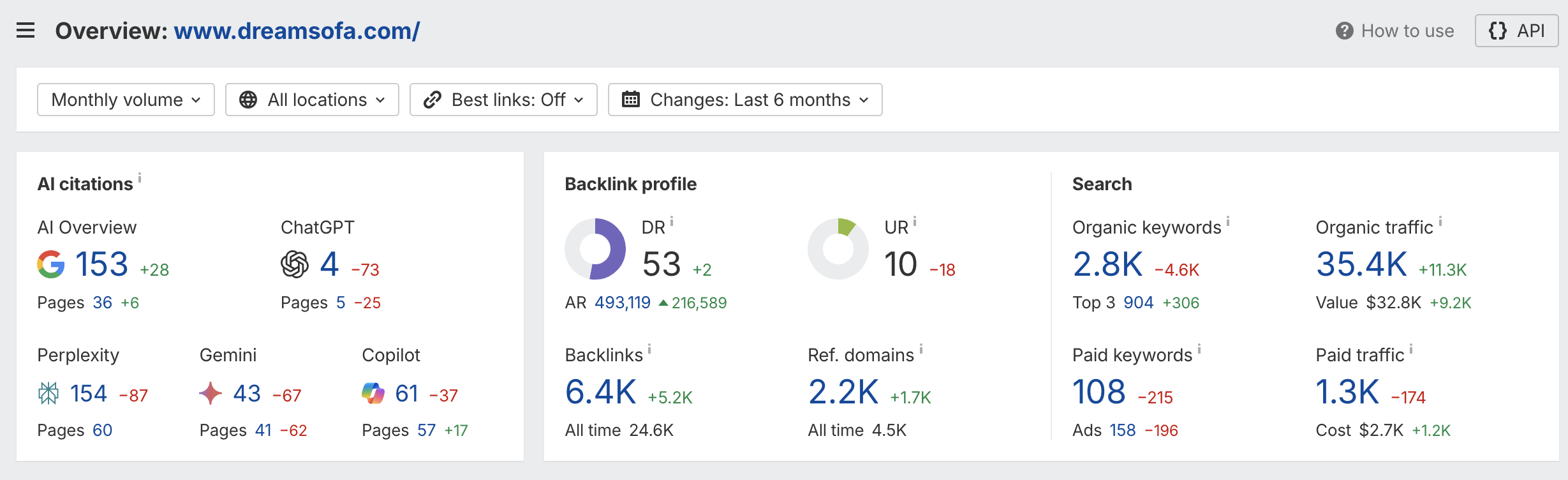
AI citation footprint across generative surfaces
After activating the GEO pipeline, DreamSofa's brand is cited across all major AI answer engines simultaneously:
- Google AI Overviews: 153 citations (+28 over 6 months) across 36 pages (+6)
- Perplexity: 154 citations across 60 pages, the highest raw citation count
- Microsoft Copilot: 61 citations across 57 pages (+17)
- Gemini: 43 citations across 41 pages
- ChatGPT: 4 citations, the lowest, reflecting ChatGPT's more conservative citation behavior for e-commerce
The multi-surface spread matters: a shopper asking "best sectional sofa for a small apartment" gets a DreamSofa citation whether they use Google, Perplexity, or Copilot. That is zero-click brand discovery at scale.
Organic search growth driven by GEO content
- Organic traffic: 35,400 sessions/month (+11,300 over 6 months)
- Organic traffic value: $32,800/month (+$9,200)
- Organic keywords: 2,800 (2,700 non-branded, growth is not from brand searches)
- Top-3 positions: 904 keywords (+306)
- Domain Rating: 53 | Referring domains: 2,200 (+1,700) | Backlinks: 6,400 (+5,200)
Key insight: The majority of organic keywords are non-branded (2,700 of 2,800). This confirms GEO-structured content is pulling in new audiences who had never searched for DreamSofa directly, exactly the zero-click-to-discovery motion GEO is designed to create.
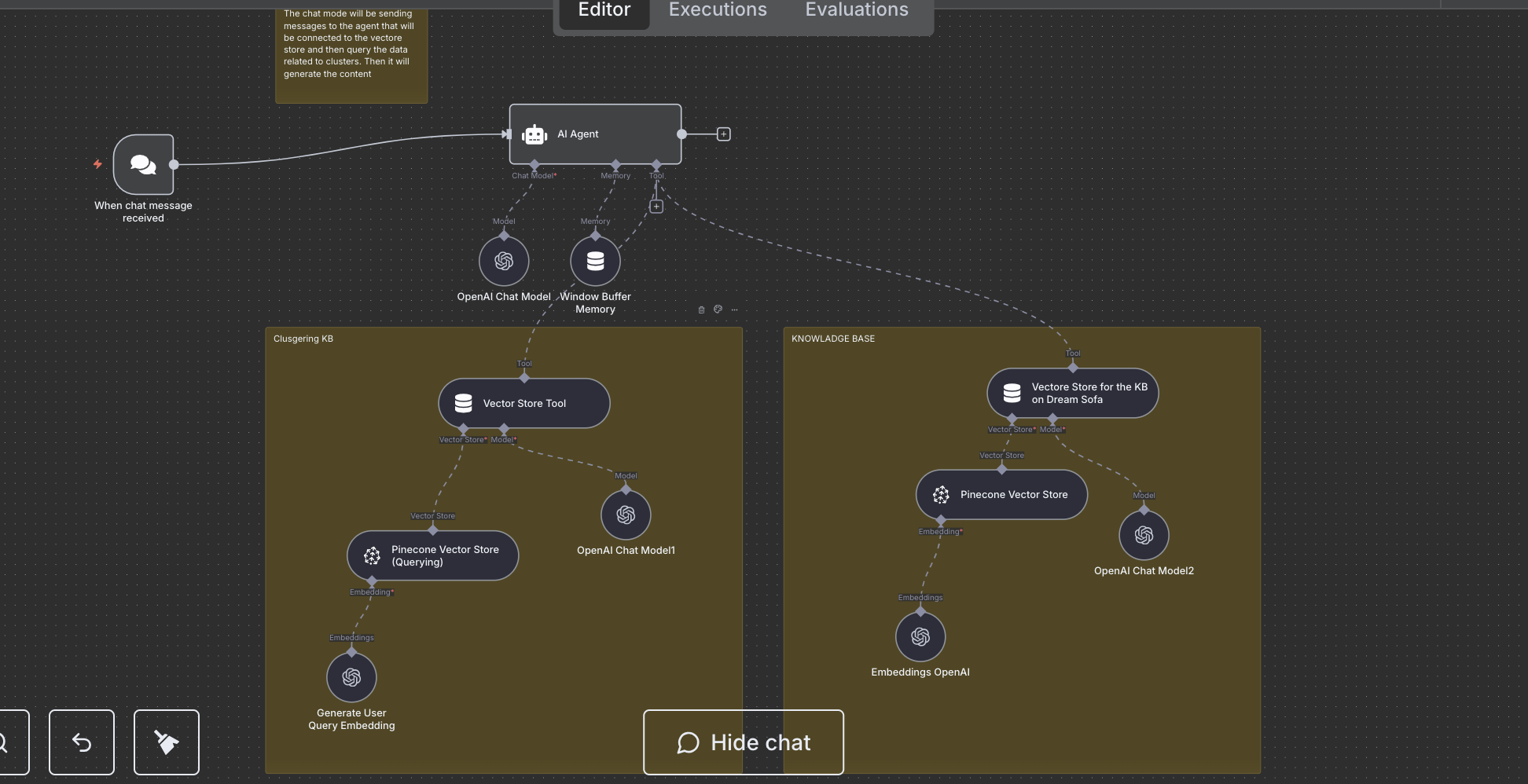
How does the DreamSofa pipeline work end-to-end?
The stack runs daily: we gather real Google queries, cluster them by meaning, store themes as long-term memory, and generate GEO-ready drafts with a chatbot that cites your Knowledge Base (KB). The outcome: trending questions + topic clusters + structured drafts aligned to user intent and E-E-A-T.
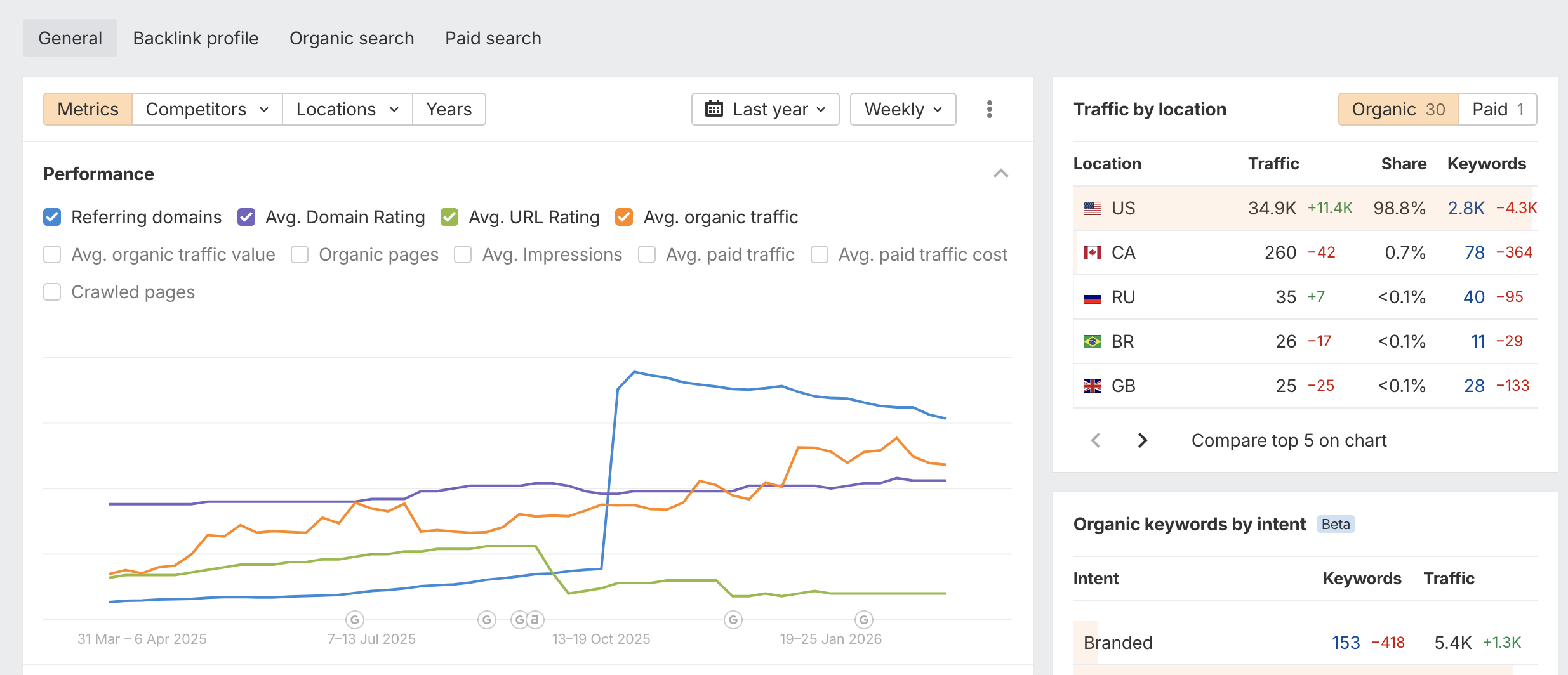
The October 2025 inflection: when the pipeline went live
The performance data shows a clear before/after. In the week of October 13-19, 2025, referring domains spiked sharply and organic traffic jumped from a baseline of ~20K to over 35K sessions per week. This inflection point aligns precisely with the full activation of the GEO content engine. Traffic is 98.8% US-based (34,900 sessions), confirming strong penetration of the primary target market, with small but growing shares in Canada (260 sessions), UK (25), and Brazil (26).
Step 1, Daily query harvesting (DataForSEO)
Every day a cron trigger collects keywords, questions, related topics, autocomplete, and subtopics from real Google searches via the DataForSEO API. We keep the "market's phrasing" fresh for ontology building and FAQ coverage instead of relying on a static keyword list.
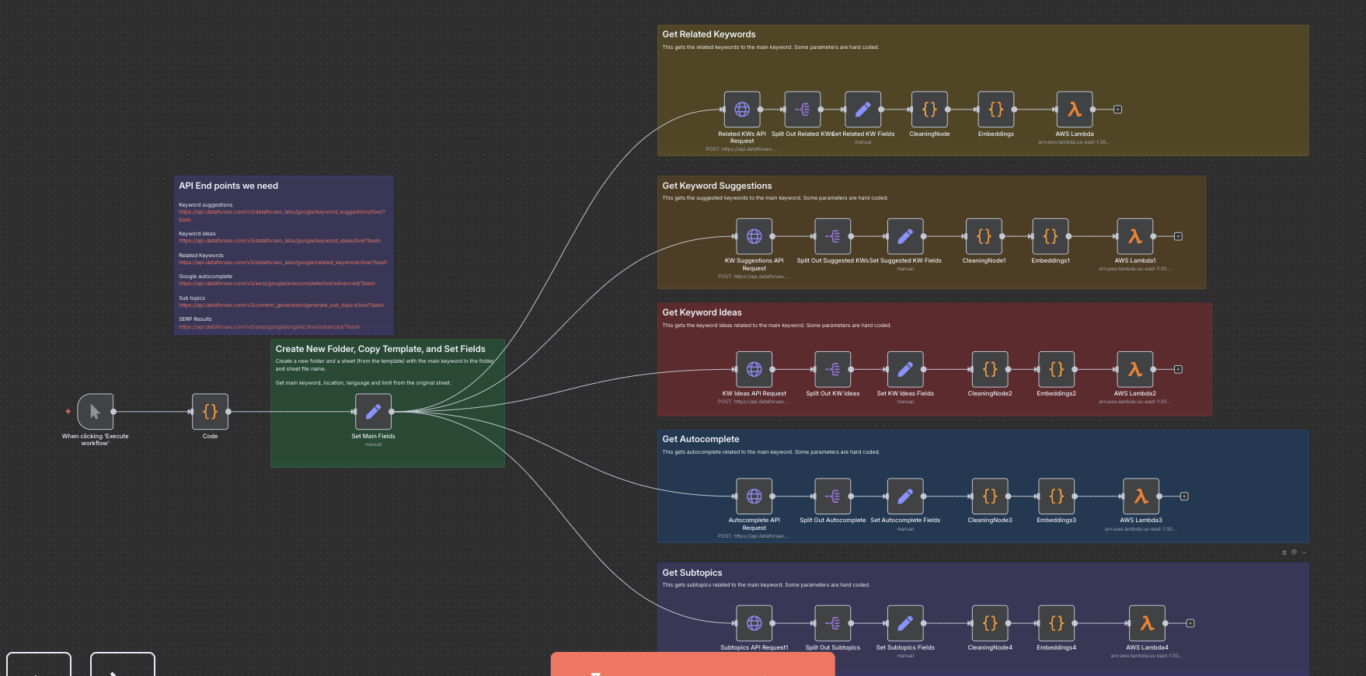
Step 2, Clustering & intent understanding
We embed queries and cluster them with HDBSCAN to reveal themes users actually care about. In the PoC we processed ~500k queries, forming 2,703 main clusters (min size 40) plus 661 additional clusters (min size 20). This yields topic maps ideal for editorial planning and FAQ coverage.
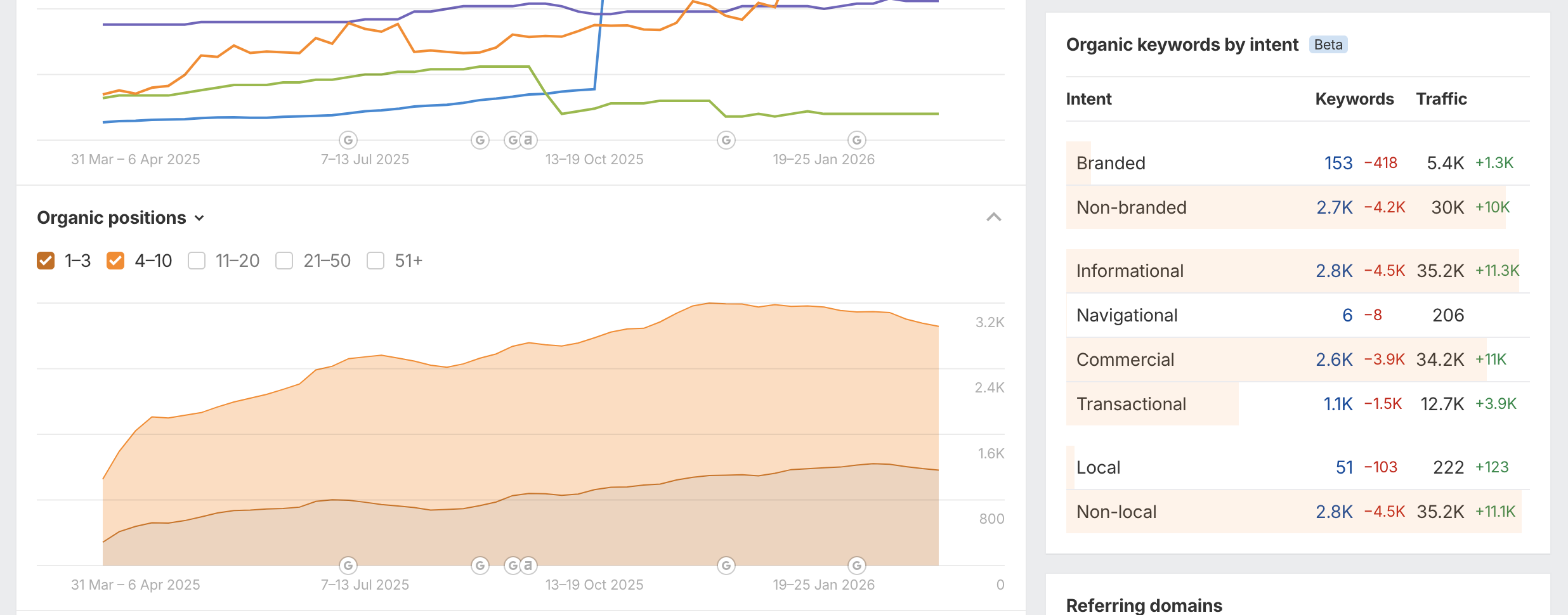
The intent breakdown validates that clustering is working as designed. When you look at Ahrefs keyword intent data for DreamSofa after pipeline activation:
- Informational: 2,800 keywords → 35,200 sessions/month (+11,300), the largest traffic category, driven directly by GEO-structured Q&A content
- Commercial: 2,600 keywords → 34,200 sessions/month (+11,000), buyers comparing and researching options
- Transactional: 1,100 keywords → 12,700 sessions/month (+3,900), ready-to-buy signals growing in parallel
- Local: 51 keywords → 222 sessions, small but growing (+123)
This distribution matches the GEO editorial strategy exactly: answer informational questions first, earn trust at the commercial stage, and convert at the transactional stage. Content built around clusters covers the full funnel without creating separate, disconnected keyword silos.
Step 3, Long-term memory in Pinecone
We load clusters into a Pinecone vector store, the system's "smart memory." The chatbot retrieves the most relevant ideas and phrasings at generation time, so drafts reflect how people actually search. Versioning and fast semantic lookups support scale without losing precision.
Step 4, Content engine with RAG
The content engine generates GEO-ready drafts using Retrieval-Augmented Generation (RAG): clusters provide current market language, your KB provides canonical facts. Prompts enforce structure (H1/H2/H3, short answers under headings, lists/tables, honest pros/cons) to maximize snippetability and citation potential.
How do we connect and govern the Knowledge Base to strengthen E-E-A-T?
The KB UI lets your team upload PDFs/DOCX/Excel/TXT, describe them, categorize, update, and deduplicate. Behind the scenes, documents are chunked and embedded so the AI can understand and cite them. This boosts trust: your articles don't "hallucinate", they reference your own materials.
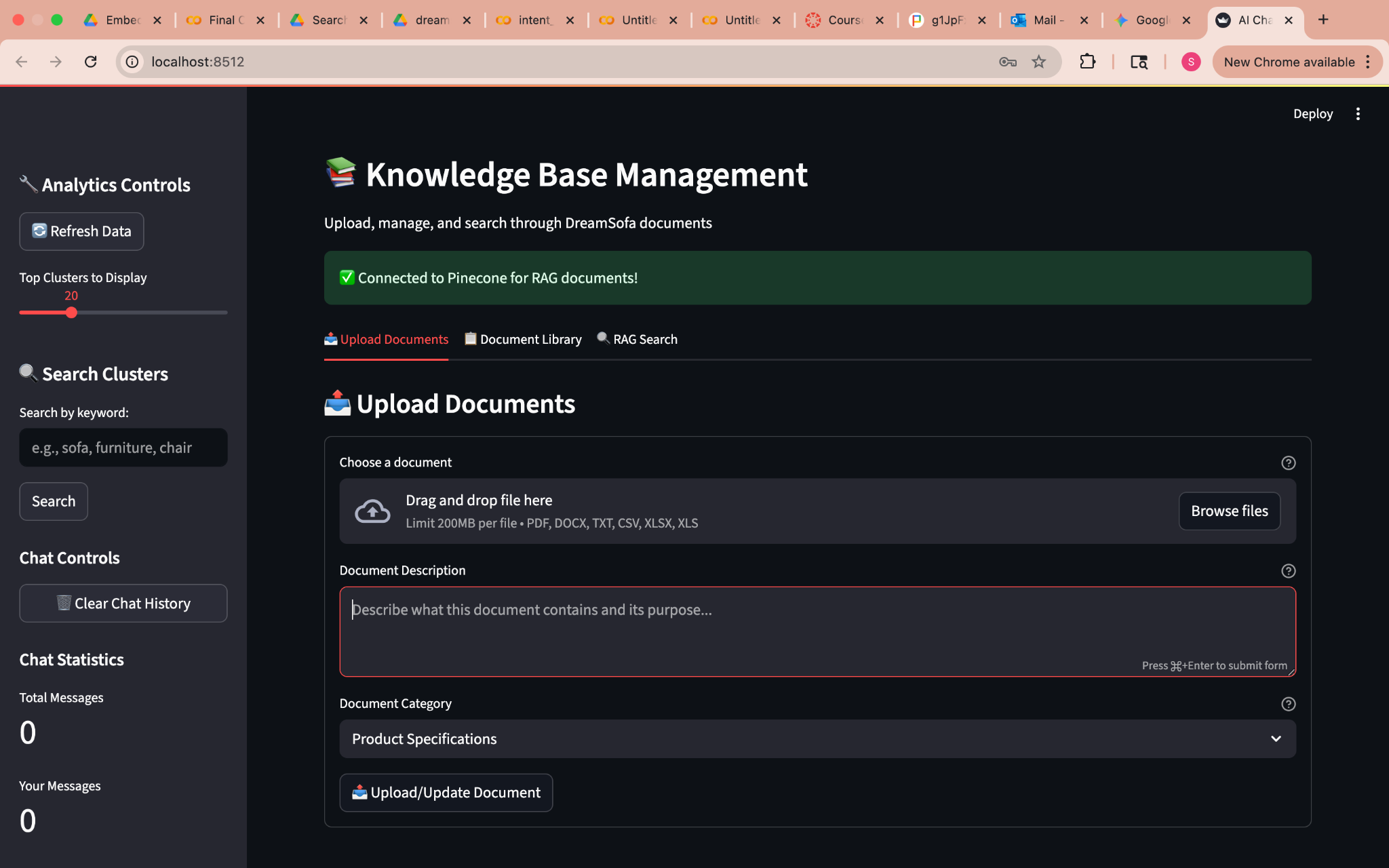
Trade-off: Stronger trust and traceability come with operational discipline, consistent descriptions, categorization, updates, and version hygiene. Without governance, RAG will surface stale chunks and degrade factual quality.
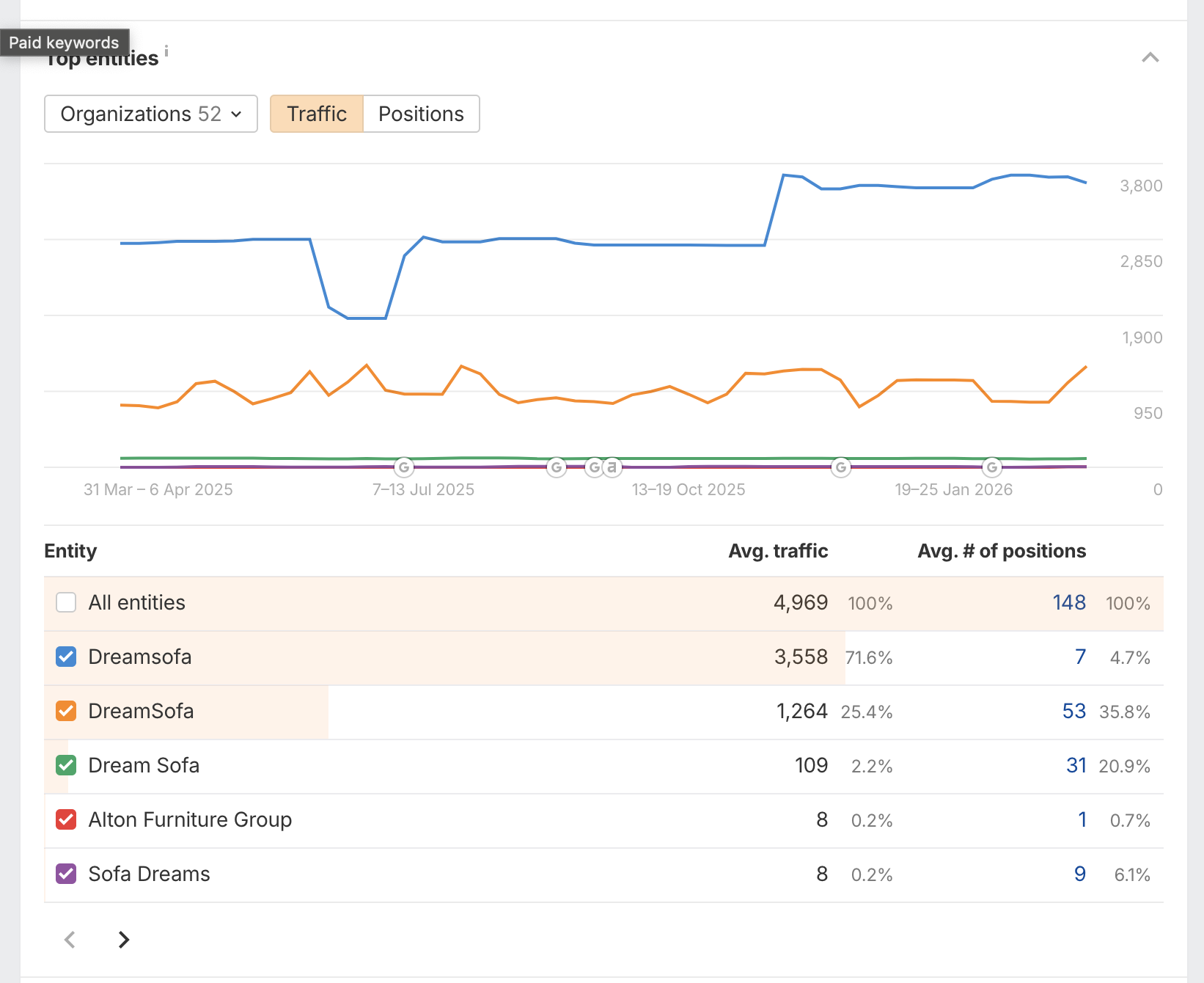
Entity recognition as a GEO health signal
One underused diagnostic is tracking how AI and search systems recognize your brand as a coherent entity. In Ahrefs' entity data for DreamSofa, the brand appears under three separate surface forms: "Dreamsofa" (lowercase) drives 3,558 avg. sessions with 7 keyword positions, "DreamSofa" (canonical CamelCase) holds 53 keyword positions with 1,264 avg. sessions, and "Dream Sofa" (with space) adds 109 sessions across 31 positions.
Entity fragmentation, the same brand appearing under multiple surface forms, dilutes authority signals sent to AI systems. When a model sees "Dreamsofa," "DreamSofa," and "Dream Sofa" as separate entities, it cannot confidently consolidate brand authority into a single citation source. Fixing this requires:
- Consistent capitalization in all owned content, schema markup, and KB entries
- JSON-LD Organization schema with a single canonical
namevalue - Ensuring press mentions and partner pages use the canonical form
- Updating the KB UI to enforce entity naming standards at upload time
The "By UR" panel in the same screenshot reveals a separate challenge: 100% of DreamSofa's 6,388 backlinks have a URL Rating below 10. While quantity has grown significantly (+5,200 links over 6 months), link quality remains low. For GEO, high-UR editorial citations from authoritative publications are more valuable as AI training signals than thousands of low-authority links. This is the next link-building priority.
How we build E-E-A-T signals into every article
Strong GEO content is not just keyword-aligned. It must also look trustworthy to both humans and AI systems. We deliberately embed Experience, Expertise, Authoritativeness, and Trustworthiness (E-E-A-T) signals into every long-form piece, product guide, and FAQ block.
Experience: real usage, real outcomes
- We include first-hand testing notes from real usage (comfort tests, fabric durability, assembly process, delivery experience) instead of generic marketing claims.
- We reference customer outcomes with specifics (e.g. "This sectional was installed in a 72 m² condo in Miami and survived two moves without frame warping").
- We add lightweight 'before / after' context or scenario photos when possible to prove we've actually handled the product.
Expertise: qualified authors, not anonymous blog posts
- Every article is published with a byline that includes relevant credentials, for example: "By Sarah Chen, Certified Interior Designer (NCIDQ), 8+ years in residential space planning."
- We cite applicable standards and specs instead of vague adjectives. For furniture this can include BIFMA/ANSI durability ratings, fabric abrasion scores (Martindale), foam densities, and warranty terms.
- We clearly distinguish opinion ("best for small apartments") from spec-backed fact ("frame is kiln-dried hardwood, not particle board").
Authoritativeness: proof we're not just guessing
- We reference external trust signals: awards, press mentions, commercial partnerships, large client installs.
- We surface recognizable comparables ("This recliner is in the same comfort class as [well-known brand model], but with modular arms for easier delivery through narrow doors").
- We link to long-term ownership data when available (e.g. 12-month wear feedback from repeat buyers, return rate percentages).
Trustworthiness: policies, guarantees, transparency
- We include return/warranty terms in plain language ("30-day no-questions return, free pickup in continental U.S.") next to the recommendation, not hidden in legal pages.
- We summarize third-party review aggregates (for example, average review score, % 4-5 star ratings, common complaints) instead of cherry-picking only praise.
- We disclose trade-offs in performance ("This sleeper sofa is comfortable for guests under 185 cm. Taller sleepers will feel foot overhang.").
Why this matters: AI systems increasingly quote content that looks like it comes from accountable humans with verifiable experience and measurable claims, not generic copy. When an answer includes bylined expertise, specific numbers, and clear limitations, it is more likely to be extracted and cited as an authoritative snippet.
How do we write GEO-ready posts models can quote?
We write from intent and ontology. At least 60% of H2s are phrased as questions. Under every H2/H3 we place a 40-60-word self-contained answer, followed by detail. We use tables/lists for clean extraction, then include case numbers and balanced pros/cons to satisfy E-E-A-T. We also attribute claims ("scratch-resistant up to 50,000 rubs on the Martindale scale") to either internal testing or manufacturer certification so both shoppers and AI models can trace where a statement came from.
- Blocks to include: entity map (features, integrations, use cases, audiences, limits), precise definitions ("X is …"), case studies with numbers, honest Pros & Cons, and a large user-language FAQ.
Trade-off: Highly scannable Q&A structures can feel less "literary." We keep brand voice in the expansion paragraphs while preserving question/answer snippets for voice search and featured-style extracts.
Balanced Pros & Cons: structured honesty the model can trust
Every product, solution, or buying path we describe ships with a dedicated Pros & Cons block. This is not generic fluff ("high quality / can be expensive"). We write specific, testable trade-offs so the reader, and the AI model, can see that we are being honest, not promotional.
Example:
- Pros: Memory foam conforms to body shape and reduces pressure points by ~30% compared to standard spring mattresses, based on reported shoulder/hip pressure relief in side sleepers.
- Cons: Retains heat and can sleep 8-10°C warmer than hybrid or gel-infused alternatives, which may be uncomfortable for hot sleepers or warm climates.
Why this matters for GEO and E-E-A-T:
- It signals trustworthiness. We are openly describing where a product is not ideal.
- It produces quotable contrast. Models like to answer "Who is this for / not for?" and will lift this exact structured language.
- It reduces buyer friction. Users scanning AI answers want "Will this work for my situation?" not just dimensions and colors.
In practice, our editorial rule is: no recommendation without a trade-off. If we say "Best for studio apartments," we must also say "Not great if you need deep seat depth for lounging." That balance increases perceived credibility for both human readers and AI systems choosing which sources to cite.
How do we measure GEO success?
We track citations inside AI answers, frequency of mentions, sentiment, and share of voice across clusters, alongside classic SEO metrics (positions, CTR, and organic sessions). Operationally, we watch pipeline stability, Pinecone latency, and the % of refreshed KB chunks to keep answers current.
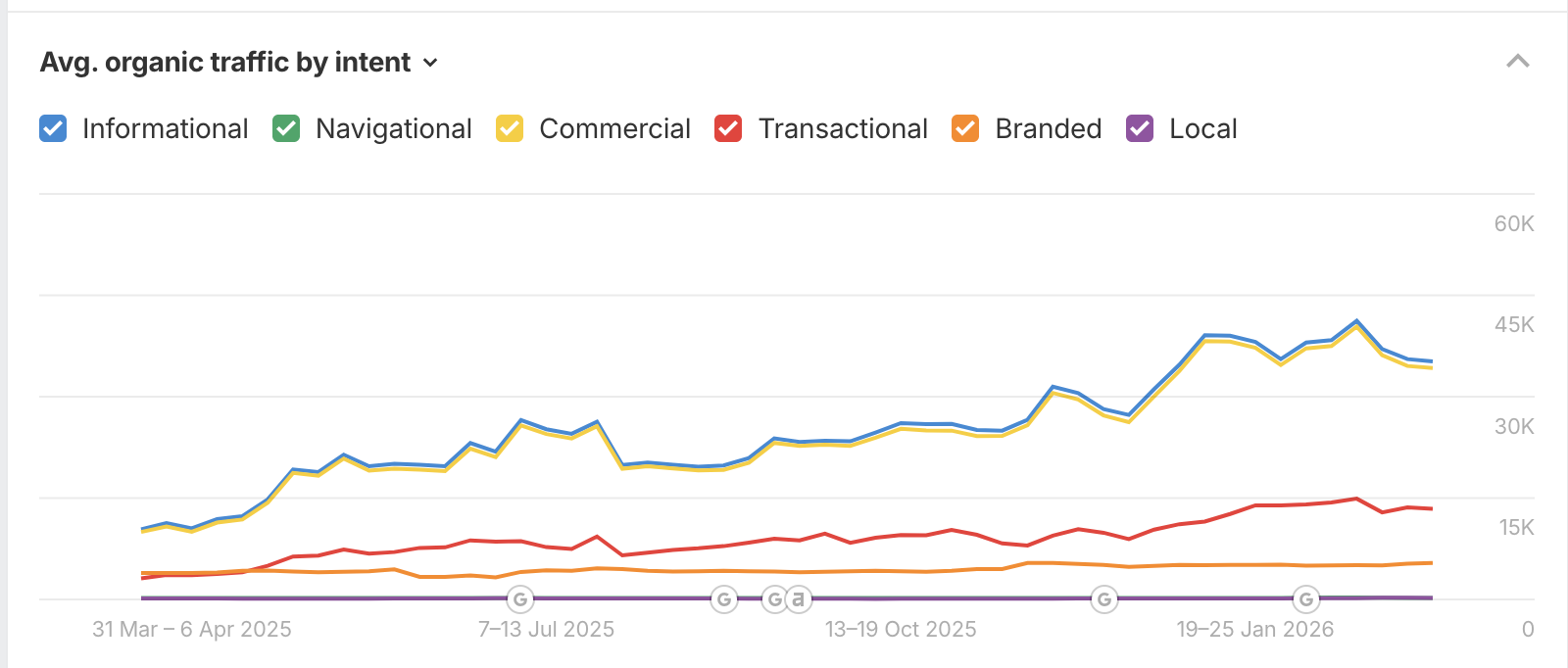
The intent-traffic trend: the cleanest GEO proof point
The single most compelling evidence that GEO content is working is the organic traffic by intent chart. From March 2025 through January 2026, informational and commercial intent traffic climbed in near-perfect parallel from roughly 20K to 45K weekly sessions. Transactional intent followed steadily, reaching 15K sessions. Branded traffic, the orange line, remained flat and low throughout.
That last point is the key signal: when branded search stays flat while non-branded informational and commercial traffic accelerates, it means new audiences are finding the brand through content, not through direct brand awareness. That is the GEO motion working as designed: answer → trust → discovery → consideration → purchase.
- Content QA: % of sections with 40-60-word answers under H2/H3, ≥10 FAQ questions in user language, clean tables/lists, explicit trade-offs in Pros & Cons, and visible E-E-A-T elements (bylined expertise, cited specs, warranty/return clarity).
- Business effects: assisted conversions where users interacted with answers/FAQ then moved to catalog or configurators.
Frequently Asked Questions
What do we collect every day and why?
Daily pulls include base keywords, questions, ideas, autocomplete, and subtopics from Google. This maintains a living record of user phrasing for entity maps, FAQ sourcing, and editorial prioritization, far richer than a one-off "semantic core."
Why HDBSCAN for clustering?
HDBSCAN handles noise and doesn't require a fixed number of clusters. With hundreds of thousands of queries, it reveals themes of varying density and filters junk, producing realistic topic groups tied to user intent.
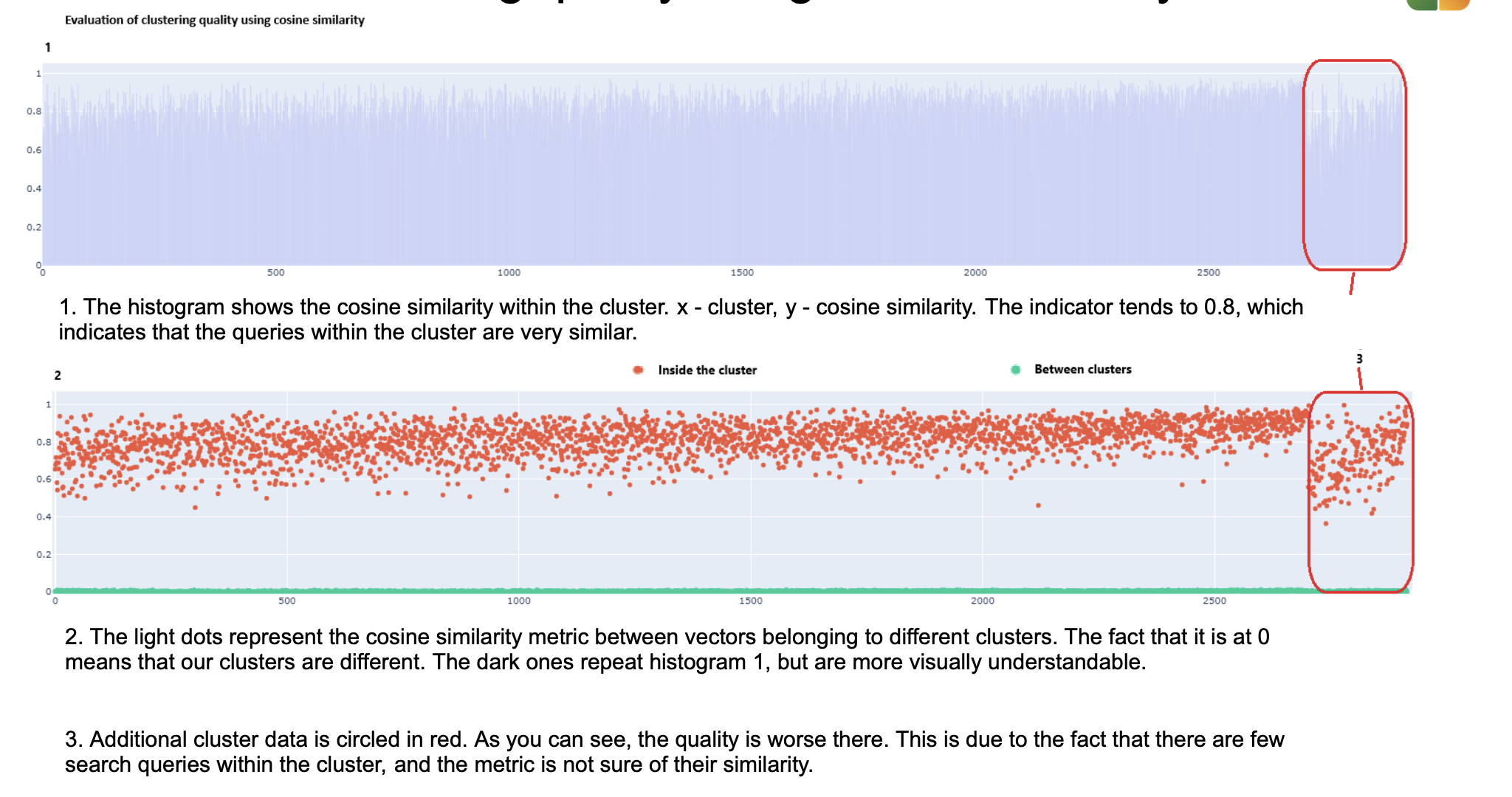
How good are the clusters?
The PoC achieved average cosine similarity within clusters of ~0.806 and between clusters of ~0.001, strong cohesion and separation. That structure lets one article answer a family of closely related questions without mixing unrelated intents.
Why Pinecone instead of a standard DB?
Vector search returns semantic matches, not only literal words. It surfaces paraphrases and neighboring formulations, improving recall and reducing intent misses during drafting and live Q&A.
What belongs in the Knowledge Base?
Catalogs, tech specs, price rules, policies, case studies, implementation guides, PDF/DOCX/XLS/TXT. The key is governance: descriptive metadata, categories, updates, and de-dup to keep RAG precise and trustworthy.
What does a GEO-standard post look like?
One H1 with the primary keyword and the year; 5-8 H2s (≥60% are questions); 40-60-word answers beneath H2/H3; big FAQ (10+ user-language questions); objective pros/cons; lists and tables for clean extraction.
How automated is the draft?
Drafting is automated; editorial judgment is not. We fact-check, add diagrams and product references, and strengthen case numbers and trade-offs, so the article is both quotable by models and genuinely useful to shoppers.
How do we reduce hallucinations?
RAG forces retrieval from Pinecone and the KB; prompts require sources and ban speculation. Short answers under headings discipline generation and make fact-checking fast for editors.
When do results show up?
Technically, soon after initial publications: citations appear in AI answers on long-tail queries. Business lift depends on niche and cadence; for furniture, early assisted-conversion signals typically surface within 4-8 weeks. The DreamSofa data shows the traffic inflection appeared roughly 2-3 weeks after October 2025 full activation.
What does the content team need to change?
Adopt the H1/H2/H3 template, write short answers first, use lists/tables, and record sources and case metrics. In return the team gets live topics, ready-made questions, and snippets from memory + KB to accelerate production.
What is entity fragmentation and why does it matter for GEO?
Entity fragmentation occurs when the same brand appears under multiple surface forms, "Dreamsofa," "DreamSofa," "Dream Sofa", in content, schema, and backlinks. Each form competes for authority rather than consolidating it. AI models use entity consistency as a trust signal: a brand that appears identically across its own content, structured data, and third-party mentions is easier to cite confidently. Fix it in JSON-LD Organization schema, in your KB naming conventions, and in editorial style guides.
Where we are now and what's next
The daily pipeline is live, the UI with Knowledge Base is built, and the content engine is wired to data. Final prompt engineering and testing are underway. Next steps: scale publications by cluster priority, monitor AI-citation share, and iterate templates by measured FAQs.
- ~500k queries processed; 2,703 main clusters + 661 additional
- Within-cluster similarity ≈ 0.806; between-cluster ≈ 0.001
- Governed KB and fast Pinecone retrieval ready for production runs
- 153 Google AI Overview citations (+28 over 6 months) | 154 Perplexity citations
- 35,400 organic sessions/month (+11,300) | Traffic value $32,800/month
- Informational + commercial intent traffic from ~20K → ~45K sessions/week since pipeline activation
- Next priority: consolidate entity representation across schema and content; improve link quality (currently 100% of backlinks at UR < 10)
As AI-powered discovery reshapes how shoppers find products, e-commerce brands face a strategic choice: wait until citation visibility becomes table stakes, or build the content and data infrastructure now while early movers still enjoy outsized share of voice. The DreamSofa pipeline is our answer to that question, and the Ahrefs data shows the motion is real: 153 AI citations on Google, 154 on Perplexity, and organic traffic growing at +11,300 sessions per month driven almost entirely by non-branded, informational and commercial queries.
The architecture, daily query ingestion, semantic clustering, vector memory, and RAG-based generation, applies to any e-commerce vertical with high SKU counts and strong informational intent. What we've validated in furniture translates directly to fashion, electronics, home goods, and specialty retail. The question isn't whether your category needs GEO infrastructure; it's whether you'll build it before or after your competitors capture the citations.